Author: Lindsay Morton, Senior Manager, Open Science Community Engagement, PLOS Registered Reports support scientific rigor, help to create a more complete scientific…
The importance of early career researchers for promoting open research
Note: This blog was originally published on the Official PLOS Blog
Author: Iain Hrynaszkiewicz, PLOS’ Director of Open Research Solutions
Early career researchers again appear to be at the vanguard of open research, with them reporting more positive attitudes towards sharing of code compared to more experienced researchers – as found in PLOS research released as a preprint this week.
At the end of March 2021 PLOS Computational Biology introduced a more stringent policy on sharing code associated with articles published in the journal. This was in response to a desire of members of the journal’s community to go further to promote open science, which appears to be reflected in the community at large – determined through collaborative research between PLOS and the journal’s community of editors and researchers.
While more than 40% of papers published in PLOS Computational Biology voluntarily shared their code already, requiring more authors to share more of their research outputs as a condition of publication is not a decision to be taken lightly by any journal. Therefore, to better understand the attitudes and experiences of the computational biology community in relation to code sharing, we designed a survey to help us understand:
- Is a mandatory code sharing policy suitable for researchers in the community?
- What proportion of researchers’ papers generate code?
- What concerns do they have about code sharing?
- How common are these concerns?
- How much would submissions to the journal be affected?
- Are there differences in different segments of researchers (regions, disciplines, career stages)?
Supporting the editorial announcing the policy and survey dataset that were released in March, a more in-depth analysis of our survey of more than 200 researchers has been released as a preprint. As well as supporting the journal’s plans, we hope this work will be a resource for other stakeholders considering adoption of new policies on sharing of code. Along with research data and protocols, sharing of code is important to help ensure research is reusable and reproducible but, as we discovered when developing the policy, there is limited evidence on the prevalence of code sharing – relative to other open research practices such as data sharing – and researchers’ experiences with sharing code and software.
The authors surveyed report that, on average, 71% of their research articles have associated code, and that for the average author, code has not been shared for 32% of these papers. A lot of researchers had not shared their code in the past due to practical or technical issues such as insufficient time, skills or systems dependencies, which — at least in principle — would not prevent compliance with a mandatory code sharing policy. Twenty two percent of respondents who had not shared their code in the past, however, cited intellectual property (IP) concerns — a legitimate issue that might prevent public sharing of code under a mandatory policy. In combination with these survey results and testing draft versions of the policy with researchers in the field, we concluded that an inclusive policy would need to permit exemptions in certain cases. However, the results also implied that more of the respondents’ previous publications could have shared code.
Figure 1. Reasons given by respondents for not sharing code publicly in the past.
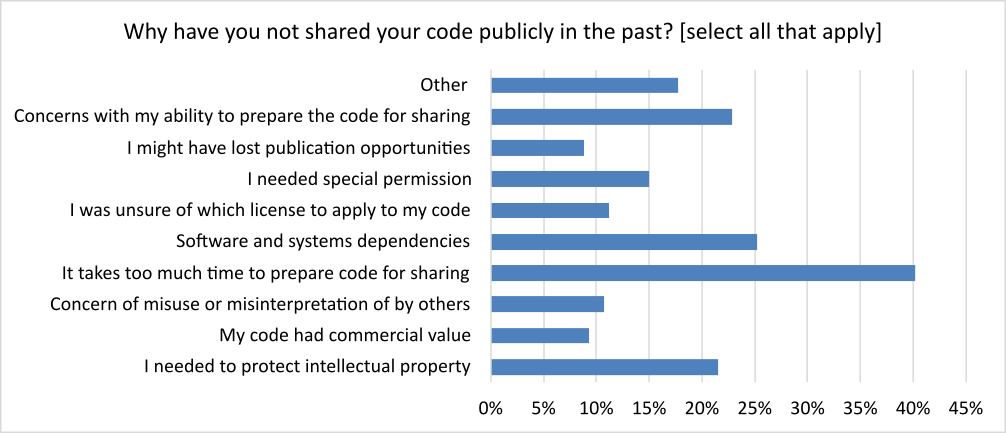
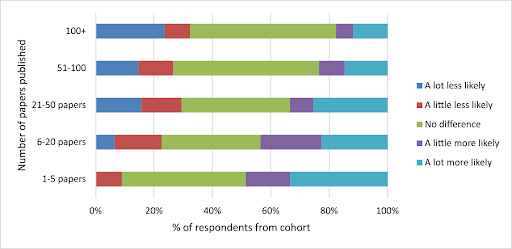
Another key finding was differences in levels of acceptance of a mandatory code sharing policy between research fields, and career stage (as determined by the number of previous publications respondents had published). Medical researchers reported being less likely to submit to the journal if it had a mandatory code sharing policy, as did researchers with more than 100 publications. Whereas, researchers with fewer than 20 published papers showed more positive responses towards submitting to the journal if it implemented a code sharing policy. Other studies have found greater affinity for open research amongst early career researchers, including a 2021 peer-reviewed survey of Early Career Researchers (ECRs) within the Max Planck society, which concluded ECRs seem to hold a generally positive view toward open research practices.
Figure 2. Respondents were asked “If PLOS Computational Biology required you to publicly share any computer code you created to interpret your results, how would this affect your likelihood to submit to the journal?”
Also, similar to what we discovered about researchers’ needs and priorities for data sharing in 2020, respondents were satisfied with their ability to share their own code but were less satisfied with their ability to access other researchers’ code. From this we infer that offering researchers new products or services to share code, at least in this community, in the absence of a stronger policy, would be unlikely to achieve the goal: of measurably increasing the availability of code with the journal’s publications. However, as with research data, we see opportunities for journals and publishers to increase findability and accessibility – and ultimately reuse – of code generated by researchers, which in turn can help realise more benefits of open research.
Read the preprint here and survey dataset here. Please note our results have not yet been peer reviewed, but will be submitted to a peer-reviewed journal soon.